Combine variables from different workflow branches into unified outputs
The Variable Aggregator node combines variables from different execution paths into a single unified output. When multiple branches produce similar outputs, this node eliminates the need for duplicate downstream processing by creating one consistent variable reference.
Conditional workflows create parallel execution paths where only one branch runs at a time. Without aggregation, you’d need duplicate downstream nodes for each possible branch outcome, creating complex and maintenance-heavy workflows.The Variable Aggregator acts as a merge point, collecting branch outputs into a single variable that downstream nodes can reference consistently, regardless of which branch actually executed.
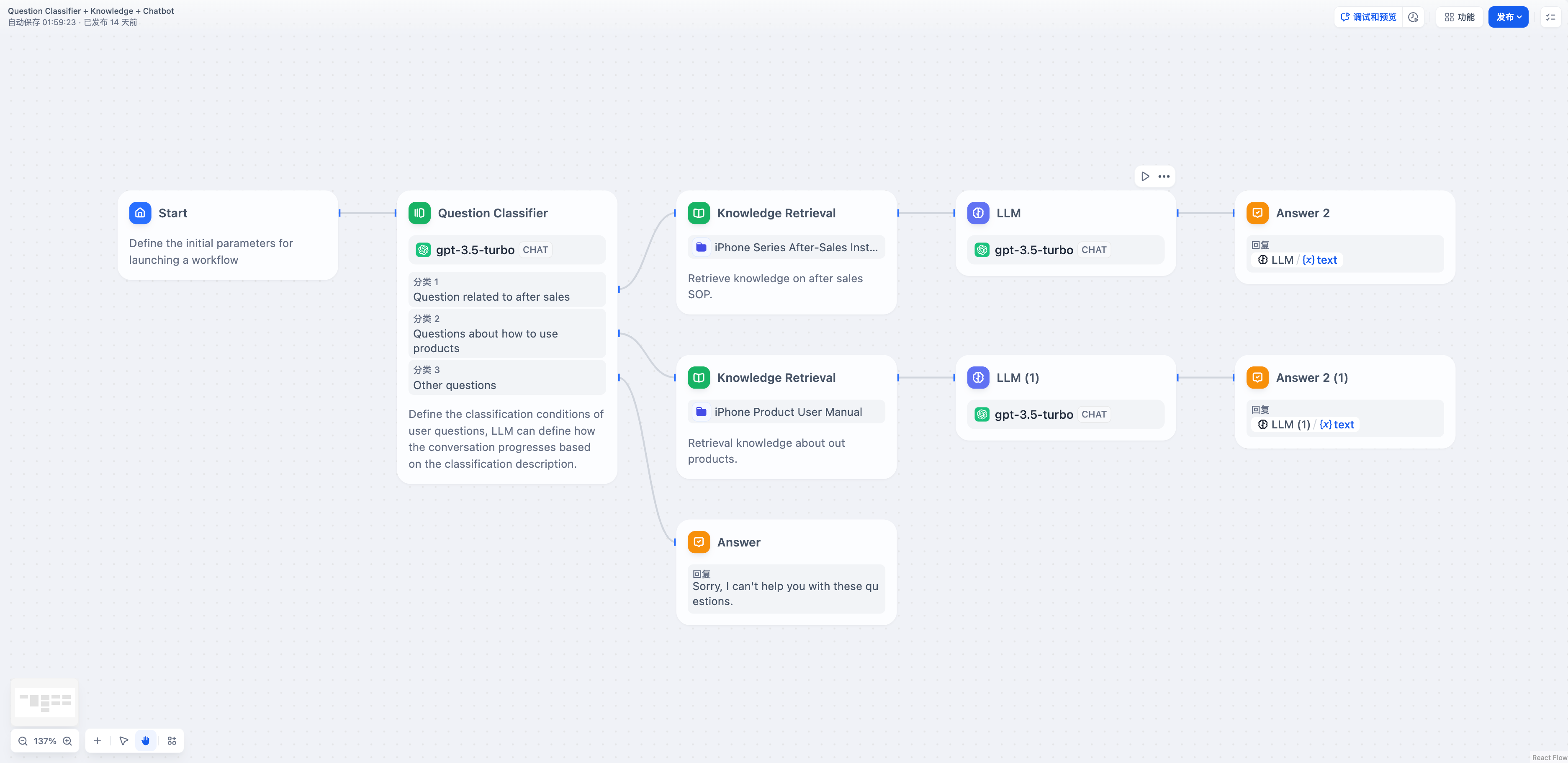
When user input is classified and each category requires different knowledge retrieval, the Variable Aggregator combines the results:Without Aggregation - Complex workflow requiring duplicate LLM nodes:
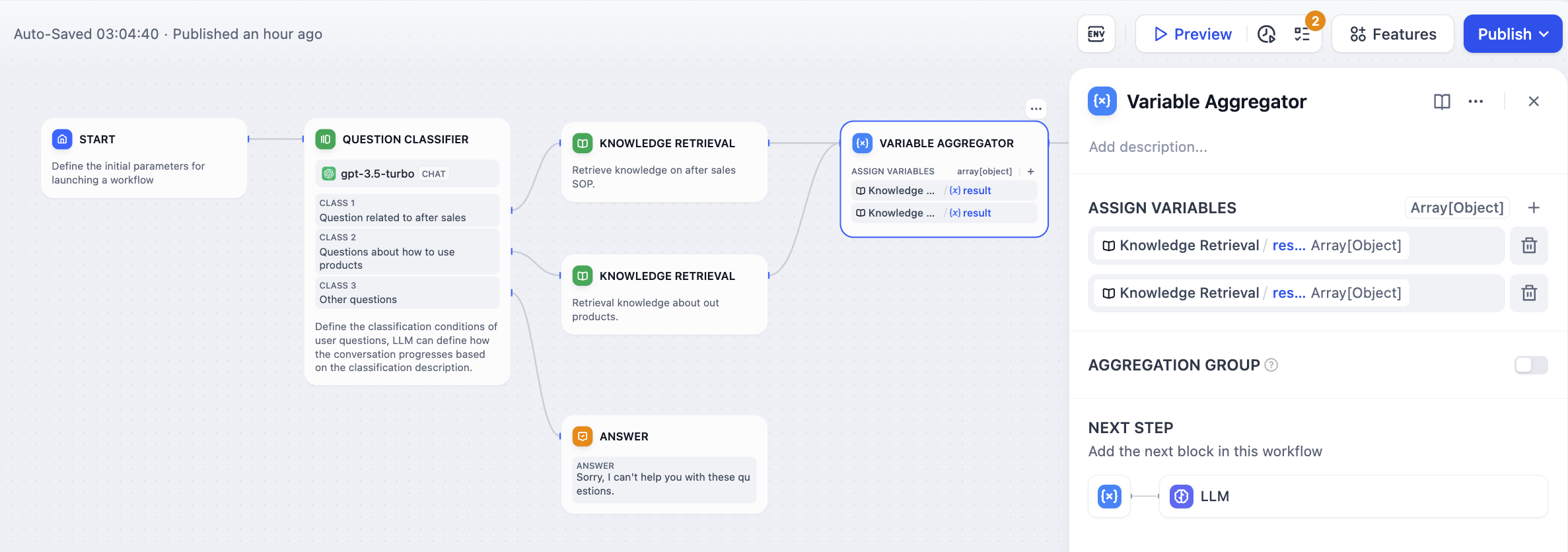
With Aggregation - Simplified workflow with single downstream processing:
The aggregated workflow uses one LLM node instead of duplicating it for each classification branch, significantly reducing complexity while maintaining the same functionality.
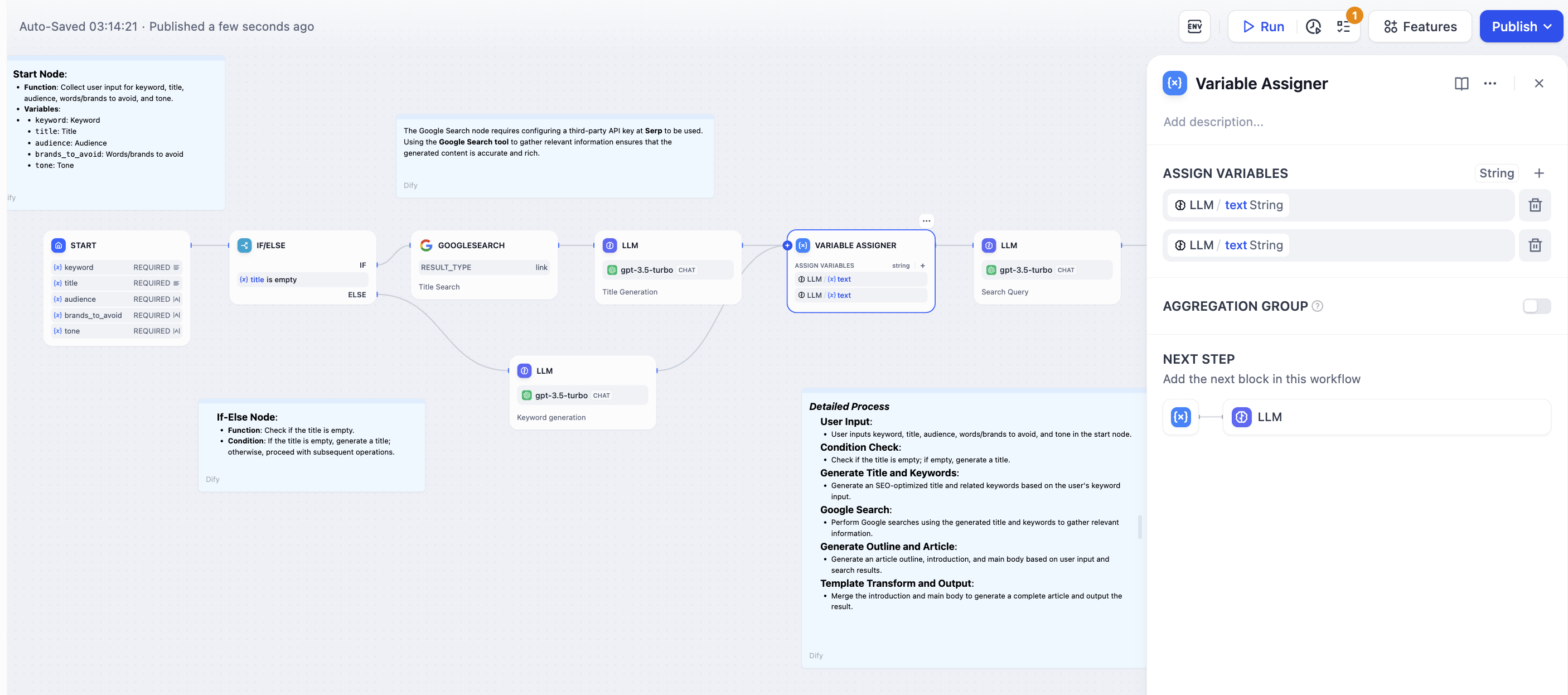
Connect variables from different workflow branches that you want to combine. Each connected variable becomes a potential input to the aggregated output.
Same Type Rule - All aggregated variables must be the same data type. Once you connect the first variable (e.g., String), the node only accepts variables of the same type from other branches.Supported Types:
String - Text outputs from different processing branches
Number - Numeric calculations, scores, or measurements
Object - Structured data objects with similar schemas
The Variable Aggregator outputs the value from whichever branch actually executed. Since only one branch runs in conditional workflows, only one input variable will have a value during execution.
Advanced workflows (v0.6.10+) can aggregate multiple groups of variables simultaneously. Each group maintains its own type constraint, allowing you to aggregate different data types in parallel within the same node.This is useful when branches produce multiple related outputs that need to be combined separately - for example, aggregating both text summaries and numeric scores from different processing paths.